ETL vs ELT: Which Approach Is Right for Your Data Pipeline?
One of the most common questions we get from clients is whether they should use ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) for their data pipelines. The answer depends on your infrastructure, data volume, and use cases.
The Traditional ETL Approach
ETL has been the standard for decades. Data is extracted from source systems, transformed in a staging area using tools like Informatica or Talend, and then loaded into a data warehouse. This approach works well when compute resources are expensive and you want to minimize what goes into your warehouse.
The Modern ELT Approach
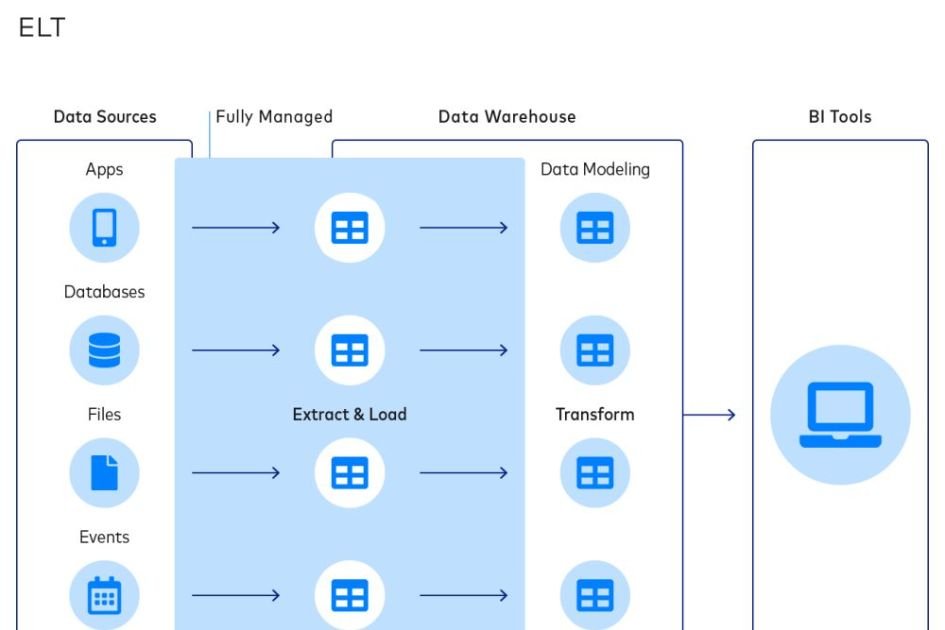
ELT flips the process. Raw data is extracted and loaded directly into a cloud warehouse like Snowflake or BigQuery, and transformations happen inside the warehouse using SQL and tools like dbt. This approach leverages the massive compute power of cloud warehouses.
When to Choose ELT
ELT shines when you’re working with cloud data warehouses that can scale compute on demand. It’s faster to set up, easier to iterate on, and gives analysts more flexibility to create their own transformations. Most modern data teams are moving toward ELT.
When ETL Still Makes Sense
ETL is still valuable when you need to reduce data volume before loading (to control costs), when you have complex transformations that don’t translate well to SQL, or when regulatory requirements demand that sensitive data be transformed before it enters your warehouse.
At FinitData, we design hybrid approaches that combine the best of both worlds based on your specific requirements.