The Data Lakehouse Architecture Explained: Best of Both Worlds
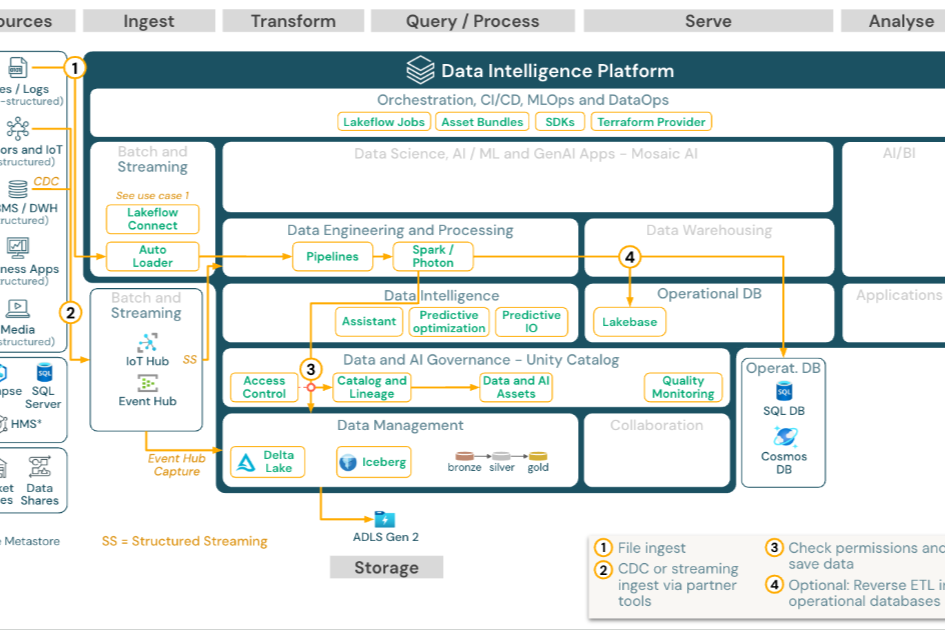
For years, organizations had to choose between a data lake (cheap storage, flexible schema, poor query performance) and a data warehouse (fast queries, structured data, expensive scaling). The lakehouse combines both into a single architecture.
How It Works
A lakehouse stores data in open file formats like Parquet on cheap object storage (S3, ADLS, GCS), but adds a metadata layer that enables warehouse-like features: ACID transactions, schema enforcement, time travel, and fast SQL queries.
Key Technologies
Delta Lake (from Databricks), Apache Iceberg, and Apache Hudi are the three main table formats that enable the lakehouse pattern. Each adds transactional guarantees and performance optimizations on top of data lake storage.
When a Lakehouse Makes Sense
The lakehouse architecture excels when you have both analytics and machine learning workloads, when you want to avoid vendor lock-in, or when you need to process a mix of structured, semi-structured, and unstructured data without maintaining separate systems.
The lakehouse isn’t a silver bullet — Snowflake and BigQuery are still excellent choices for pure analytics workloads. But for organizations that need flexibility at scale, the lakehouse is increasingly the architecture of choice.